Elman, Dive into the Latest on Long-Context Language Modeling
Hi Elman,
In this newsletter, we'll explore the cutting edge of long-context language modeling, a field rapidly evolving to address the limitations of traditional LLMs. We'll delve into four recent papers that introduce novel architectures and training strategies designed to enable efficient processing of extensive text sequences, even within resource-constrained environments. From infinite context processing to hybrid architectures and optimized training methodologies, these innovations promise to unlock new possibilities for LLMs in a wide range of applications.
InfiniPot: Achieving Infinite Context with Continual Distillation
InfiniPot: Infinite Context Processing on Memory-Constrained LLMs by Minsoo Kim, Kyuhong Shim, Jungwook Choi, Simyung Chang https://arxiv.org/abs/2410.01518
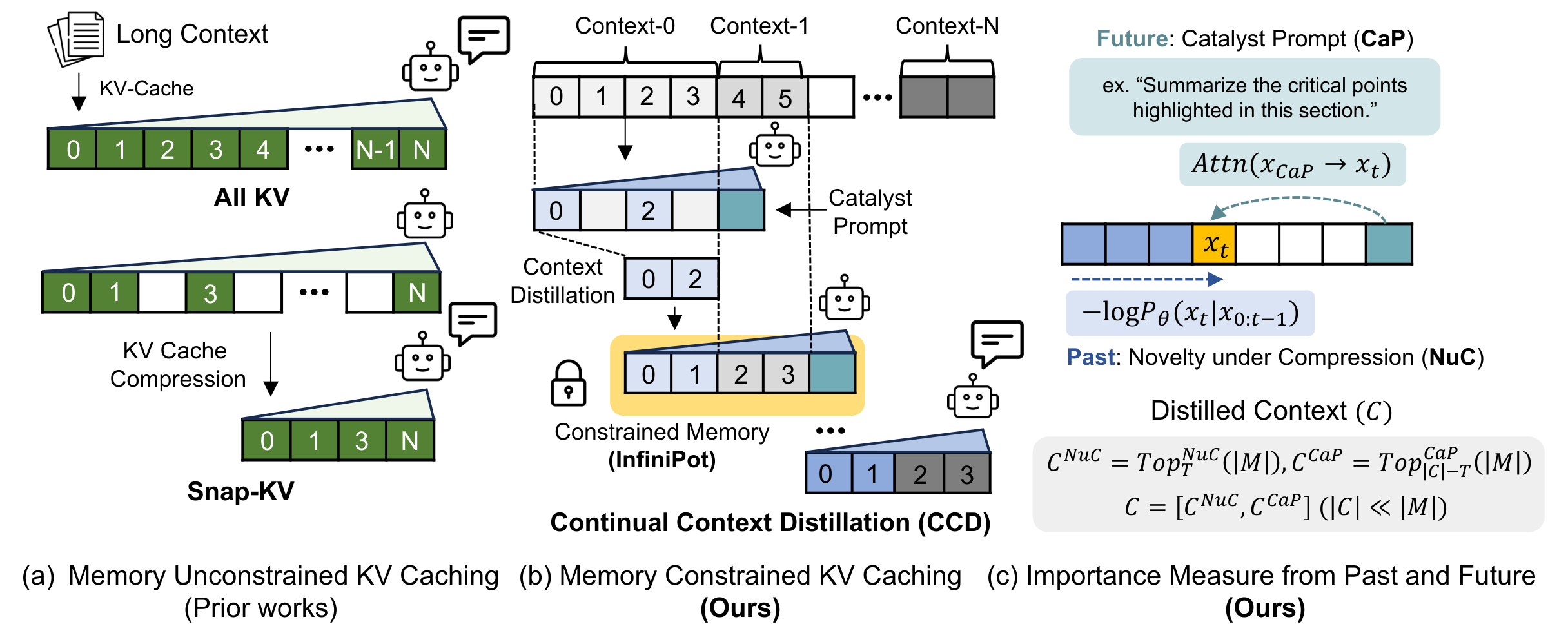 Caption: The figure illustrates InfiniPot's Continual Context Distillation (CCD) process. It shows how InfiniPot uses Catalyst Prompts (CaP) and Novelty under Compression (NuC) to selectively distill and retain crucial information from a long context within a constrained memory, enabling processing of theoretically infinite context lengths by iteratively compressing the Key-Value cache.
Caption: The figure illustrates InfiniPot's Continual Context Distillation (CCD) process. It shows how InfiniPot uses Catalyst Prompts (CaP) and Novelty under Compression (NuC) to selectively distill and retain crucial information from a long context within a constrained memory, enabling processing of theoretically infinite context lengths by iteratively compressing the Key-Value cache.
Large Language Models (LLMs) have undeniably revolutionized NLP, but their constrained context window remains a significant bottleneck, especially on resource-limited devices. Traditional solutions, like expanding memory or streaming inputs, present their own limitations. Memory expansion is often infeasible for on-device deployments, while streaming approaches can sacrifice overall comprehension by prioritizing recent context.
InfiniPot offers a groundbreaking solution: a novel Key-Value (KV) cache control framework designed to enable pre-trained LLMs to process theoretically infinite contexts within fixed memory constraints, all without requiring further training. This remarkable capability is achieved through Continual Context Distillation (CCD), an iterative process that intelligently compresses and retains crucial information through innovative importance metrics.
CCD relies on two key components: the Catalyst Prompt (CaP) and the Novelty under Compression (NuC) score. CaP, strategically injected before the KV-cache reaches capacity, guides attention score generation, effectively approximating future token importance within a finite context. NuC, on the other hand, prioritizes novel information not previously encountered by the pre-trained model or preceding context. This combination allows InfiniPot to discern and preserve the most vital information, efficiently managing long contexts through multiple CCD cycles. Additionally, a Context-Reset Rotary Positional Embedding (CR-ROPE) policy prevents out-of-distribution issues arising from compressed contexts.
Evaluations on LongBench and the Needle In A Haystack (NIH) test showcase InfiniPot's impressive performance. On LongBench, it achieves competitive scores even with memory constraints, rivaling and sometimes surpassing memory-unconstrained models. On NIH, InfiniPot maintains high accuracy even with exceptionally long contexts, demonstrating superior scalability compared to other long-context models. Furthermore, its consistent performance across varying context lengths, combined with optimized memory usage and high throughput, highlights its efficiency.
LONGGEN: A Hybrid Approach to Efficient Long-Context Processing
A Little Goes a Long Way: Efficient Long Context Training and Inference with Partial Contexts by Suyu Ge, Xihui Lin, Yunan Zhang, Jiawei Han, Hao Peng https://arxiv.org/abs/2410.01485
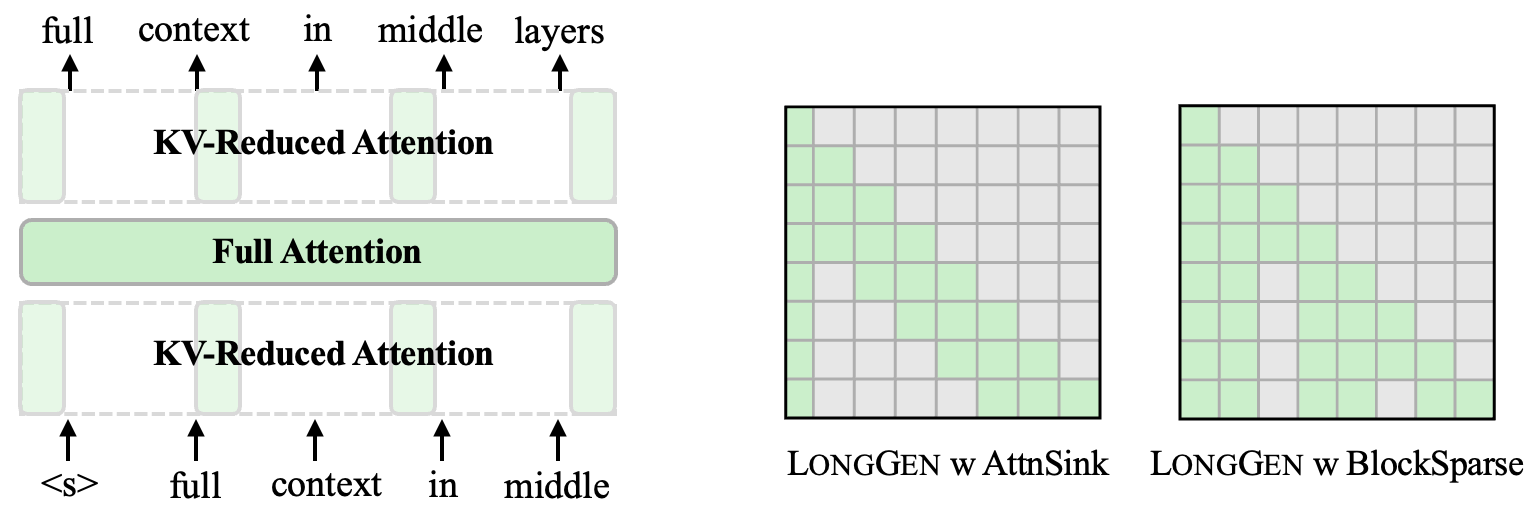 Caption: The image depicts the architecture of LONGGEN, showing a hybrid approach of combining full attention layers (green block) with KV-reduced attention layers (green and grey striped blocks) for efficient long-context language modeling. The arrows indicate the flow of full context information within the middle layers. The two grids on the right illustrate different sparse attention patterns employed by LONGGEN, AttnSink and BlockSparse, for reducing KV cache memory and improving efficiency.
Caption: The image depicts the architecture of LONGGEN, showing a hybrid approach of combining full attention layers (green block) with KV-reduced attention layers (green and grey striped blocks) for efficient long-context language modeling. The arrows indicate the flow of full context information within the middle layers. The two grids on the right illustrate different sparse attention patterns employed by LONGGEN, AttnSink and BlockSparse, for reducing KV cache memory and improving efficiency.
Training and serving long-context LLMs comes with significant computational overhead. LONGGEN addresses this by integrating context length extension with a GPU-friendly KV cache reduction architecture, resulting in both reduced training overhead and enhanced long-context performance.
LONGGEN's effectiveness is built upon three key insights. First, it utilizes sparse attention patterns like window attention, attention sink, and blockwise sparse attention. These patterns are inherently GPU-friendly due to their memory access patterns, translating theoretical efficiency gains into practical speedups. Second, LONGGEN adopts a hybrid architecture, combining full attention layers with efficient sparse attention layers. This hybrid approach allows the model to directly access all tokens while maintaining efficiency. Third, it shows that training on a relatively small dataset of long-context data can significantly extend the model's context window.
The results on Llama-2 models are compelling. LONGGEN achieves substantial training speedups and significant reductions in wall-clock time compared to full-attention baselines. During inference, the reduced KV cache translates to significant speed improvements in both prefilling and decoding. These improvements are due to the reduced computational requirements of sparse attention, especially when the context length (N) is much larger than the block size (S) used in sparse attention (S ≪ N).
ProLong: Optimizing Training for Long-Context Mastery
How to Train Long-Context Language Models (Effectively) by Tianyu Gao, Alexander Wettig, Howard Yen, Danqi Chen https://arxiv.org/abs/2410.02660
Training LLMs for effective long-context understanding requires a nuanced approach. This paper advocates for a more robust evaluation protocol, focusing on a diverse set of long-context tasks and evaluating models after supervised fine-tuning (SFT). This approach provides a more accurate assessment of a model's true long-context capabilities.
The research highlights several critical findings. Combining code repositories and books—excellent sources of long data—with high-quality short data proves crucial for maintaining performance on shorter contexts. Surprisingly, training with sequences longer than the evaluation length enhances long-context performance. Furthermore, using standard, short-context instruction datasets for SFT is sufficient for achieving strong long-context performance.
The resulting model, ProLong-8B, achieves state-of-the-art long-context performance among similarly sized models, outperforming larger models trained on significantly more data. Its ability to handle extremely long contexts positions it at the forefront of publicly available long-context LLMs. This work challenges common assumptions and underscores the importance of comprehensive evaluation and careful data curation.
Locret: Efficient Eviction for Long-Context Inference
Locret: Enhancing Eviction in Long-Context LLM Inference with Trained Retaining Heads by Yuxiang Huang, Binhang Yuan, Xu Han, Chaojun Xiao, Zhiyuan Liu https://arxiv.org/abs/2410.01805
 Caption: The diagram illustrates LOCRET's retaining head architecture, which predicts Causal Importance Scores (CIS) for key-value cache units based on Q, K, and V vectors. The lower section visualizes the chunked prefill and cache eviction process, where low-CIS units are removed while stabilizers maintain local context continuity within a fixed cache size b.
Caption: The diagram illustrates LOCRET's retaining head architecture, which predicts Causal Importance Scores (CIS) for key-value cache units based on Q, K, and V vectors. The lower section visualizes the chunked prefill and cache eviction process, where low-CIS units are removed while stabilizers maintain local context continuity within a fixed cache size b.
Scaling LLMs for long contexts poses significant memory challenges, especially on consumer-grade GPUs. LOCRET addresses this by introducing trained retaining heads that evaluate the importance of KV cache units, enabling more accurate and efficient eviction.
LOCRET adds small, trainable retaining heads to the LLM architecture. These heads learn to predict the causal importance of each KV cache unit. During inference, a chunked prefill pattern is used, and the retaining heads guide the eviction process, prioritizing the removal of less important units. Stabilizers ensure local context continuity despite the eviction process.
Empirical evaluations show that LOCRET outperforms existing methods in both memory efficiency and generated content quality. It achieves remarkable KV cache compression ratios, enabling long-context inference on resource-constrained hardware. Furthermore, its compatibility with other efficient inference techniques, like quantization and token merging, highlights its versatility and potential.
Conclusion: A New Era for Long-Context LLMs
This newsletter has showcased several innovative approaches to tackling the challenges of long-context language modeling. From InfiniPot’s continual distillation enabling theoretically infinite context processing to LONGGEN’s hybrid architecture balancing performance and efficiency, and from ProLong's optimized training strategies to Locret's intelligent KV cache eviction, these advancements represent significant progress. The convergence of these techniques promises a future where LLMs can seamlessly process and understand extensive textual information, unlocking new applications and pushing the boundaries of natural language processing.